Fitting Algorithms¶
Summary of Available Algorithms¶
| Algorithm | Class | Parallelization | Applications |
|---|---|---|---|
| Differential Evolution | Population-based | Synchronous or Asynchronous | General-purpose parameter fitting |
| Scatter Search | Population-based | Synchronous | General-purpose parameter fitting, especially difficult problems with high dimensions or many local minima |
| Particle Swarm | Population-based | Asynchronous | Fitting models with high variability in runtime |
| Metropolis-Hastings MCMC | Metropolis sampling | Independent Markov Chains | Finding probability distributions of parameters (deprecated) |
| Simulated Annealing | Metropolis sampling | Independent Markov Chains | Problem-specific applications (deprecated) |
| Parallel Tempering | Metropolis sampling | Synchronized Markov Chains | Finding probability distributions in challenging probablity landscapes (deprecated) |
| Simplex | Local search | Synchronous | Local optimization, or refinement of a result from another algorithm. |
| Adaptive MCMC | Metropolis sampling | Independent Markov Chains | Finding probability distributions in challenging probablity landscapes |
General implementation features for all algorithms¶
All algorithms in PyBNF keep track of a list of parameter sets (a “population”), and over the course of the simulation, submit new parameter sets to run on the simulator. Algorithms periodically output the file sorted_params.txt containing the best parameter sets found so far, and the corresponding objective function values.
Initialization¶
The initial population of parameter sets is generated based on the keys specified for each free parameter: uniform_var, loguniform_var, normal_var or lognormal_var. The value of the parameter in each new random parameter set is drawn from the specified probability distribution.
The latin_hypercube option for initialization is enabled by default. This option only affects initialization of uniform_vars and loguniform_vars. When enabled, instead of drawing an independent random value for each starting parameter set, the starting parameter sets are generated with Latin hypercube sampling, which ensures a roughly even distribution of the parameter sets throughout the search space.
Objective functions¶
All algorithms use an objective function to evaluate the quality of fit for each parameter set. The objective function is set with the objfunc key. The following options are available. Note that 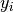 are the experimental data points and
are the experimental data points and 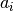 are the simulated data points. The summation is over all experimental data points.
are the simulated data points. The summation is over all experimental data points.
- Chi squared (
obj_func = chi_sq):, where
is the standard deviation of point
- Sum of squares (
obj_func = sos):- Sum of differences (
obj_func = sod):- Normalized sum of squares (
obj_func = norm_sos):- Average-normalized sum of squares (
obj_func = ave_norm_sos):, where
is the average of the entire data column
.
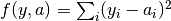
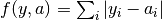
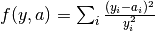
If you include any constraints in your fit, the constraints add extra terms to the objective function.
Changing parameter values¶
All algorithms perform changes to parameter values as the fitting proceeds. The way these changes are calculated depends on the type of parameter.
loguniform_vars and lognormal_vars are moved in logarithmic space (base 10) throughout the entire fitting run.
uniform_vars and loguniform_vars avoid moving outside the defined initialization range. If a move is attempted that would take the parameter outside the bounds, the parameter value is reflected over the boundary, back within bounds. This feature can be disabled by appending U to the end of the variable definition (e.g. uniform_var = x__FREE 10 30 U)
Differential Evolution¶
Algorithm¶
A population of individuals (points in parameter space) are iteratively evaluated with an objective function. Parent individuals from the current iteration are selected to form new individuals in the next iteration. The new individual’s parameters are derived by combining parameters from the parents. New individuals are accepted into the population if they have an objective value lower than that of a member of the current population.
Parallelization¶
Three versions of differential evolution are available: All run in parallel, but they differ in their level of synchronicity.
Asynchronous differential evolution (fit_type = ade) never allows processors to sit idle. One new simulation is started every time a simulation completes. This version is the best choice when a large number of processors are available.
Synchronous differential evolution (fit_type = de) consists of discrete iterations. In each iteration, n simulations are run in parallel, but all must complete before moving on to the next iteration.
Island-based differential evolution [Penas2015] is partially asynchronous algorithm. To use this version, set fit_type = de and set a value greater than 1 for the islands key. In this version, the current population consists of m islands. Each island is able to move on to the next iteration even if other islands are still in progress. If m is set to the number of available processors, then processors will never sit idle. Note however that this might still underperform compared to the synchronous algorithm run on the same number of processors.
Implementation details¶
We maintain a list of population_size current parameter sets, and in each iteration, population_size new parameter sets are proposed. The method to propose a new parameter set is specified by the config key de_strategy. The default setting rand1 works best for most problems, and runs as follows: We choose 3 random parameter sets p1, p2, and p3 in the current population. For each free parameter P, the new parameter set is assigned the value p1[P] + mutation_factor * (p2[P]-p3[P]) with probability mutation_rate, or p1[P] with probability 1 - mutation_rate. The new parameter set replaces the parameter set with the same index in the current population if it has a lower objective value.
With de_strategy of best1 or best2, we force the above p1 to be the parameter set with the lowest objective value. With de_strategy of all1 or all2, we force p1 to be the parameter set at the same index we are proposing to replace. The best strategy results in fast convergence to what is likely only a local optimum. The all strategy converges more slowly, and prevents the entire population from converging to the same value. However, there is still a risk of each member of the population becoming stuck in its own local minimum. For the de_strategys ending in 2, we instead choose a total of 5 parameter sets, p1 through p5, and set the new parameter value as p1[P] + mutation_factor * (p2[P]-p3[P] + p4[P]-p5[P])
Asynchronous version¶
The asynchronous version of the algorithm is identical to the sychronous algorithm, except that whenever a simulation completes, a new parameter set is immediately proposed based on the current population. Therefore, the random parameter sets p1, p2, and p3 might come from different iteration numbers.
Island-based version¶
In the island-based version of the algorithm [Penas2015], the population is divided into num_islands islands, which each follow the above update procedure independently. Every migrate_every iterations, a migration step occurs in which num_to_migrate individuals from each island are transferred randomly to others (according to a random permutation of the islands, keeping the number of individuals on each island constant). The migration step does not require synchronization of the islands; it is performed when the last island reaches the appropriate iteration number, regardless of whether other islands are already further along.
Applications¶
In our experience, differential evolution tends to be a good general-purpose algorithm.
The asynchronous version has similar advantages to Particle Swarm.
Scatter Search¶
Algorithm¶
Scatter Search [Glover2000] functions similarly to differential evolution, but maintains a smaller current population than the number of available processors. In each iteration, every possible pair of individuals are combined to propose a new individual.
Parallelization¶
In a scatter search run of population size n, each iteration requires n*(n-1) independent simulations that can all be run in parallel. Scatter search requires synchronization at the end of each iteration, waiting for all simulations to complete before moving to the next iteration.
Implementation details¶
The PyBNF implementation follows the outline presented in the introduction of [Penas2017] and uses the recombination method described in [Egea2009].
We maintain a reference set of population_size individuals, recommended to be a small number (~ 9-18). Each newly proposed parameter set is based on a “parent” parameter set and a “helper” parameter set, both from the current reference set. In each iteration, we consider all possible parent-helper combinations, for a total of n*(n-1) parameter sets. The new parameter set depends on the rank of the parent and helper (call them 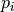 and
and 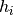 ) when the reference set is sorted from best to worst.
) when the reference set is sorted from best to worst.
Then we apply a series of formulas to choose the next parameter value.
Let 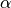 = -1 if
= -1 if 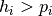 or 1 if
or 1 if 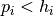 , let
, let 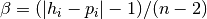 , let
, let ![d = \textrm{helper}[P] - \textrm{parent}[P]](_images/math/0564519b01eb8de6190d05dc3c698f1f905640ef.png) for some parameter P.
for some parameter P.
Then the in the new parameter set, ![P = \textrm{parent}[P] + \textrm{rand\_uniform}(-d * (1 + \alpha * \beta), d * (1 - \alpha * \beta))](_images/math/48d25d568ffd34e3b3962dd9310fb02d7eac16cb.png)
Intuitively what we do here is perturb P on the order of d (which acts as a measure of the variability of P in the population). If the parent is better than the helper, we keep P closer to the parent, and if the helper is better, we shift it closer to the helper.
The proposed new parameter set is accepted if it achieves a lower objective value than its parent.
If a parent goes local_min_limit iterations without being replaced by a new parameter set, it is assumed to be stuck in a local minimum, and is replaced with a new random parameter set. The random parameter set is drawn from a “reserve queue”, which is initialized at the start of the fitting run to contain reserve_size Latin hypercube distributed samples. The reserve queue ensures that each time we take a new random parameter set, we are sampling a part of parameter space that we have not sampled previously.
Applications¶
We find scatter search is also a good general-purpose fitting algorithm. It performs especially well on fitting problems that are difficult due to a search space that is high dimensional or contains many local minima.
Particle Swarm¶
Algorithm¶
In particle swarm optimization, each parameter set is represented by a particle moving through parameter space at some velocity. The acceleration of each particle is set in a way that moves it toward more favorable areas of parameter space: the acceleration has contributions pointing toward both the best parameter set seen so far by the individual particle, and the global best parameter set seen by any particle in the population.
Parallelization¶
Particle swarm optimization in PyBNF is an asynchronous, parallel algorithm. As soon as one simulation completes, that particle can calculate its next parameter set and begin a new simulation. Processors will never remain idle.
Implementation details¶
The PyBNF implementation is based on the description in [Moraes2015]. Each particle keeps track of its current position, velocity, and the best parameter set it has seen during the run.
After each simulation completes, the velocity of the particle is updated according to the formula 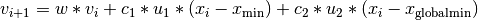 . The constants in the above formula may be set with config keys: w is
. The constants in the above formula may be set with config keys: w is particle_weight, 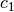 is
is cognitive, and 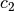 is
is social. 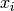 is the current particle position,
is the current particle position, 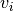 is the current velocity,
is the current velocity, 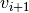 is the updated velocity,
is the updated velocity,  is the best parameter set this particle has seen, and
is the best parameter set this particle has seen, and 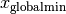 is the best parameter set any particle has seen.
is the best parameter set any particle has seen. 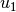 and
and 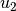 are uniform random numbers in the range [0,1]. Following the velocity update, the position of the particle is updated by adding its current velocity.
are uniform random numbers in the range [0,1]. Following the velocity update, the position of the particle is updated by adding its current velocity.
We apply a special treatment if a uniform_var or loguniform_var moves outside of the specified box constraints. As with other algorithms, the particle position is reflected back inside the boundaries. In addition, the component of the velocity corresponding to the parameter that moved out of bounds is set to zero, to prevent the particle from immediately crossing the same boundary again.
An optional feature (discussed in [Moraes2015]) allows the particle weight w to vary over the course of the simulation. In the original algorithm descirption, w was called “inertia weight”, but when w takes a value less than 1, it can be thought of as friction - a force that decelerates particles regardless of the objective function evaluations. The idea is to reduce w (increase friction) over the course of the fitting run, to make the particles come to a stop at a good objective value by the end of the run.
When using the adaptive friction feature, w starts at particle_weight, and approaches particle_weight_final by the end of the simulation. The value of w changes based on how many iterations we deem “unproductive” according to the following criterion: An iteration is unproductive if the global best objective function obj_min changes by less than adaptive_abs_tol + adaptive_rel_tol * obj_min, where adaptive_abs_tol and adaptive_rel_tol can be set in the config. Then, we keep track of N, the total number of unproductive iterations so far. At each iteration we set w = particle_weight + (particle_weight_final - particle_weight) * N / (N + adaptive_n_max). As can be seen in the above formula, the config key adaptive_n_max sets the number of unproductive iterations it takes to reach halfway between particle_weight and particle_weight_final.
Applications¶
Particle swarm optimization tends to be the best-performing algorithm for problems that benefit from asynchronicity, namely, models for which the runtime per simulation can vary greatly depending on the parameter set. Models simulated by SSA or NFsim often fall into this category. In these cases, synchronous algorithms would cause some cores to remain idle while slow-running simulations complete on other cores, whereas asynchronous algorithms like particle swarm allow you to use all cores at all times.
Metropolis-Hastings MCMC¶
Algorithm¶
Metropolis-Hastings Markov chain Monte Carlo (MCMC) is a Bayesian sampling method. The free parameters are taken to be random variables with unknown probability distributions, and the algorithm samples points in parameter space are sampled with a frequency proportional to the probability of the parameter set given the data. The result is a probability distribution over parameter space that expresses the probability of each possible parameter set. With this algorithm, we obtain not just a point estimate of the best fit, but a means to quantify the uncertainty in each parameter value.
When running this algorithm in PyBNF, it is assumed that the objective function is a likelihood function, that is, the objective function value gives the negative log probability of the data given the parameter set. There is a solid mathematical basis for making this assumption when the chi-squared objective function is used. It is not recommended to use this algorithm with different objective function, or an objective function that includes qualitative data.
PyBNF outputs additional files containing this probability distribution information. The files in Results/Histograms/ give histograms of the marginal probability distributions for each free parameter. The files credible##.txt (e.g., credible95.txt) use the marginal histogram for each parameter to calculate a credible interval - an interval in which the parameter value is expected to fall with the specified probability (e.g. 95%). Finally, samples.txt contains all parameter sets sampled over the course of the fitting run, allowing the user to perform further custom analysis on the sampled probability distribution.
Parallelization¶
Metropolis-Hastings is not an inherently parallel algorithm. In the Markov chain, we need to know the current state before proposing the next one. However, PyBNF supports running several independent Markov chains by specifying the number of chains with the population_size key. All samples from all parallel chains are pooled to obtain a better estimate of the final posterior probability distribution.
Note that each chain must independently go through the burn-in period, but after the burn-in, your rate of sampling will be improved proportional to the number of parallel chains in your run.
Implementation details¶
Our implementation is described in [Kozer2013]. We start at a random point in parameter space, and make a step of size step_size to move to a new location in parameter space. We take the value of the objective function to be the negative log probability of the data given the parameter set (the likelihood in Bayesian statistics). We assume a prior distribution based on the parameter definitions in the config file – a uniform, loguniform, normal, or lognormal distribution, depending on the config key used. Note: If a uniform or loguniform prior is used, the prior does not affect the result other than to confine the distribution within the specified range. If a normal or lognormal prior is used, the prior does affect the probability of accepting each proposed move, and therefore the choice of prior affects the final sampled probability distribution.
The Bayesian posterior distribution – the probability of the parameters given the data – is given by the product of the above likelihood and prior. We use the value of the posterior to determine whether to accept the proposed move.
Moves are accepted according to the Metropolis criterion. If a move increases the value of the posterior, it is always accepted. If it decreases the value of the posterior, it is accepted with probability 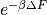 , where
, where 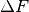 is the change in the posterior, and
is the change in the posterior, and 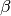 represents the inverse “temperature” at which the Metropolis sampling occurs. To generate the true posterior distribution, should be set to 1. The sampled distribution becomes more broad with smaller and more narrow with a larger .
represents the inverse “temperature” at which the Metropolis sampling occurs. To generate the true posterior distribution, should be set to 1. The sampled distribution becomes more broad with smaller and more narrow with a larger .
Applications¶
Metropolis-Hastings is the simplest method available in PyBNF to generate a probability distribution in parameter space.
Simulated Annealing¶
Algorithm¶
Simulated annealing is another Markov chain-based algorithm, but our goal is not to find a full probability distribution, just find the optimal parameter set. To do so, we start the Markov chain at a high temperature, where unfavorable moves are accepted frequently, and gradually reduce the temperature over the course of the simulation. The idea is that we will explore parameter space broadly at the start of the fitting run, and become more confined to the optimal region of parameter space as the run proceeds.
Parallelization¶
Simulated annealing is not an inherently parallel algorithm. The trajectory is a Markov chain in which we need to know the current state before proposing the next one. However, PyBNF supports running several independent simulated annealing chains in parallel. By running many chains simulatenously, we have a better chance that one of the chains achieves a good final fit.
Implementation details¶
The Markov chain is implemented in the same way as described above for the Markov chain Monte Carlo algorithm, incorporating both the objective function value and the prior distribution to calculate the posterior probability density.
The difference is in the Metropolis criterion for acceptance of a proposed move. Here, a move that decreases the value of the posterior is accepted with probability , where decreases over the course of the fitting run.
Applications¶
We have not found any problems for which simulated annealing is better than the other available algorithms, but provide the functionality with the hope that it proves useful for some specific problems.
Parallel Tempering¶
Algorithm¶
Parallel tempering is a more sophisticated version of Markov chain Monte Carlo (MCMC). We run several Markov chains in parallel at different temperatures. At specified iterations during the run, there is an opportunity to exchange replicates between the different temperatures. Only the samples recorded at the lowest temperature count towards our final probability distribution, but the presence of the higher temperature replicates makes it easier to escape local minima and explore the full parameter space.
When running parallel tempering, PyBNF outputs files containing probability distribution information, the same as with Metropolis-Hastings MCMC.
Like Metropolis-Hastings, it is recommended to only use parallel tempering with the chi-squared objective function.
Parallelization¶
The replicates are run in parallel. Synchronization is required at every iteration in which we attempt replica exchange.
Implementation details¶
The PyBNF implementation is based on the description in [Gupta2018a]. Markov chains are run by the same method as in Metropolis-Hastings, except that the value of in the acceptance probability varies between replicas.
Every exchange_every iterations, we attempt replica exchange. We propose moves that consist of swapping two replicas between adjacent temperatures. Moves are accepted with probability 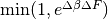 where
where 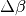 is the change in = 1/Temperature, and is the difference in the objective values of the replicas. In other words, moves that transfer a lower-objective replica to a lower temperature (higher ) are always accepted, and those that transfer a higher-objective replica to a lower temperature are accepted with a Metropolis-like probability based on the extent of objective difference.
is the change in = 1/Temperature, and is the difference in the objective values of the replicas. In other words, moves that transfer a lower-objective replica to a lower temperature (higher ) are always accepted, and those that transfer a higher-objective replica to a lower temperature are accepted with a Metropolis-like probability based on the extent of objective difference.
The list of s used is customizable with the beta or beta_range key. The number of replicas per temperature is also customizable. To maintain detailed balance, it is required that each temperature contains the same number of replicas.
Applications¶
Like conventional Metropolis-Hastings MCMC, the goal of parallel tempering is to provide a distribution of possible parameter values rather than a single point estimate.
Compared to Metropolis-Hastings MCMC, parallel tempering offers a trade-off: Parallel tempering generates fewer samples per unit CPU time (because most of the processors run higher temperature simulations that don’t sample the distribution of interest), but traverses parameter space more efficiently, making each sample more valuable. The decision between parallel tempering and Metropolis-Hastings therefore depends on the nature of your parameter space: parallel tempering is expected to perform better when the space is complex, with many local minima that make it challenging to explore.
Adaptive MCMC¶
Algorithm¶
Adaptive Markov chain Monte Carlo (MCMC) is a Bayesian sampling method. The Bayesian method is described in further detail under the Metropolis-Hasting definition. When running this algorithm in PyBNF, it is assumed that the objective function is a likelihood function, that is, the objective function value gives the negative log probability of the data given the parameter set. It is recommended that the Chi-squared or negative binomial or their dynamic versions are used with this algorithm. The output when using the adaptive MCMC in PyBNF consists of the posterior from each chain and a file containing parameters from all chains saved in the ‘/Results/AMCMC/Run’ folder.
Parallelization¶
Like Metropolis-Hastings, Adaptive MCMC is not an inherently parallel algorithm. Like the Metropolis-Hastings algorithm PyBNF supports running several independent Markov chains using the populations_size key. Note as stated in the Metropolis-Hastings description each chain must independently go through the burn-in period, but after the burn-in, your rate of sampling will be improved proportional to the number of parallel chains in your run.
Implementation details¶
The implementation algorithm can be found in Andrieu and Thoms, Stat Comput 18: 343–373 (2008). The algorithm uses a random walk like MCMC during the training period. While in the training period data is collected to determine the covariance of the posterior. Once the training phase is completed real time on the fly calculation of the diffusivity and covariance is performed for the remaining iterations. Note: as stated in the Metropolis-Hastings description if a uniform or loguniform prior is used, the prior does not affect the result other than to confine the distribution within the specified range. If a normal or lognormal prior is used, the prior does affect the probability of accepting each proposed move, and therefore the choice of prior affects the final sampled probability distribution.
Simplex¶
Algorithm¶
Simplex is a local search algorithm that operates solely on objective evaluations at single points (i.e. it does not require calculation of gradients). The algorithm maintains a set on N+1 points in N-dimensional parameter space, which are thought of as defining an N-dimensional solid called a simplex. Individual points may be reflected through the lower-dimensional solid defined by the other N points, to obtain a local improvement in objective function value. The simplex algorithm has been nicknamed the “amoeba” algorithm because the simplex crawls through parameter space similar to an amoeba, extending protrusions in favorable directions.
Parallelization¶
The PyBNF Simplex implementation is parallel and synchronous. Synchronization is required at the end of every iteration. Parallelization is achieved by simultaneously evaluating a subset of the N+1 points in the simplex. Therefore, this parallelization can take advantage of at most N+1 processors, where N is the number of free parameters.
Implementation details¶
PyBNF implements the parallelized Simplex algorithm described in [Lee2007].
The initial simplex consists of N+1 points chosen deterministically based on the specified step size (set with the simplex_step and simplex_log_step keys, or for individual parameters with the var and log_var keys). One point of the simplex is the specified starting point for the search. The other N points are obtained by adding the step size to one parameter, and leaving the other N-1 parameters at the starting values.
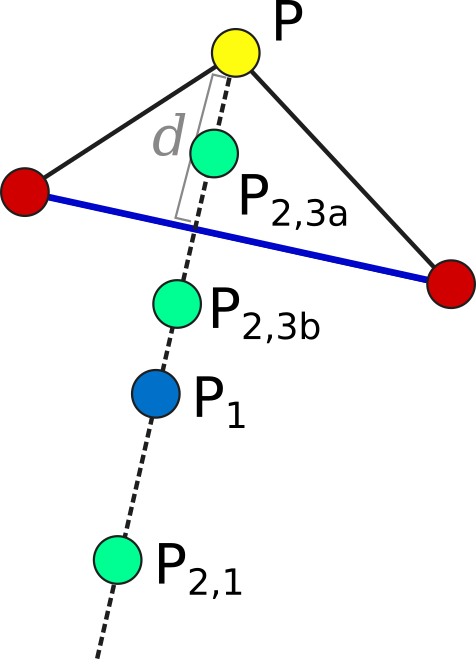
Illustration of the simplex algorithm, modifying point P on a 3-point simplex in 2 dimensions
Each iteration, we operate on the k worst points in the simplex, where k is the number of available processors (parallel_count). For each point P, we consider the hyperplane defined by the other N points in the simplex (blue line). Let d be the distance from P to the hyperplane. We evaluate point P1 obtained by reflecting P through the hyperplane, to a distance of d * simplex_reflect on the other side. Depending on the resulting objective value, we try another point in the second phase of the iteration. Three cases are possible.
- The new point is better than the current global minimum: We try a second point continuing in the same direction for a distance of d *
simplex_expansionaway from the hyperplane (P2,1). - The new point is worse than the global minimum, but better than the next worst point in the simplex: We don’t try a second point.
- The new point is worse than the next worst point in the simplex: We try a second point moving closer to the hyperplane. If P was better than P1, we try a point a distance of d *
simplex_contractionfrom the hyperplane in the direction of P (P2,3a). If P1 was better than P, we instead try the same distance from the hyperplane in the direction of P1 (P2,3b).
In all cases, P in the simplex is set to the best choice among P, P1, or whichever second point we tried.
If in a given iteration, all k points resulted in Case 3 and did not update to P2,3a or P2,3b, the iteration did not effectively change the state of the simplex. Then, we contract the simplex towards the best point: We set each point P to simplex_contract * P0 + (1 - simplex_contract) * P, where P0 is the best point in the simplex.
Applications¶
Local optimization with the simplex algorithm is useful for improving on an already known good solution. In PyBNF, the most common application is to apply the simplex algorithm to the best-fit result obtained from one of the other algorithms. You can automatically refine your final result with the simplex algorithm by setting the refine key to 1, and setting simplex config keys in addition to the config for your main algorithm.
It is also possible to run the Simplex algorithm on its own, using a custom starting point. In this case, you should use the var and log_var keys to specify your known starting point.
| [Egea2009] | Egea, J. A.; Balsa-Canto, E.; García, M.-S. G.; Banga, J. R. Dynamic Optimization of Nonlinear Processes with an Enhanced Scatter Search Method. Ind. Eng. Chem. Res. 2009, 48 (9), 4388–4401. |
| [Glover2000] | Glover, F.; Laguna, M.; Martí, R. Fundamentals of Scatter Search and Path Relinking. Control Cybern. 2000, 29 (3), 652–684. |
| [Gupta2018a] | Gupta, S.; Hainsworth, L.; Hogg, J. S.; Lee, R. E. C.; Faeder, J. R. Evaluation of Parallel Tempering to Accelerate Bayesian Parameter Estimation in Systems Biology. 2018 26th Euromicro International Conference on Parallel, Distributed and Network-based Processing (PDP) 2018, 690–697. |
| [Kozer2013] | Kozer, N.; Barua, D.; Orchard, S.; Nice, E. C.; Burgess, A. W.; Hlavacek, W. S.; Clayton, A. H. A. Exploring Higher-Order EGFR Oligomerisation and Phosphorylation—a Combined Experimental and Theoretical Approach. Mol. BioSyst. Mol. BioSyst 2013, 9 (9), 1849–1863. |
| [Lee2007] | Lee, D.; Wiswall, M. A Parallel Implementation of the Simplex Function Minimization Routine. Comput. Econ. 2007, 30 (2), 171–187. |
| [Moraes2015] | (1, 2) Moraes, A. O. S.; Mitre, J. F.; Lage, P. L. C.; Secchi, A. R. A Robust Parallel Algorithm of the Particle Swarm Optimization Method for Large Dimensional Engineering Problems. Appl. Math. Model. 2015, 39 (14), 4223–4241. |
| [Penas2015] | (1, 2) Penas, D. R.; González, P.; Egea, J. A.; Banga, J. R.; Doallo, R. Parallel Metaheuristics in Computational Biology: An Asynchronous Cooperative Enhanced Scatter Search Method. Procedia Comput. Sci. 2015, 51 (1), 630–639. |
| [Penas2017] | Penas, D. R.; González, P.; Egea, J. A.; Doallo, R.; Banga, J. R. Parameter Estimation in Large-Scale Systems Biology Models: A Parallel and Self-Adaptive Cooperative Strategy. BMC Bioinformatics 2017, 18 (1), 52. |